
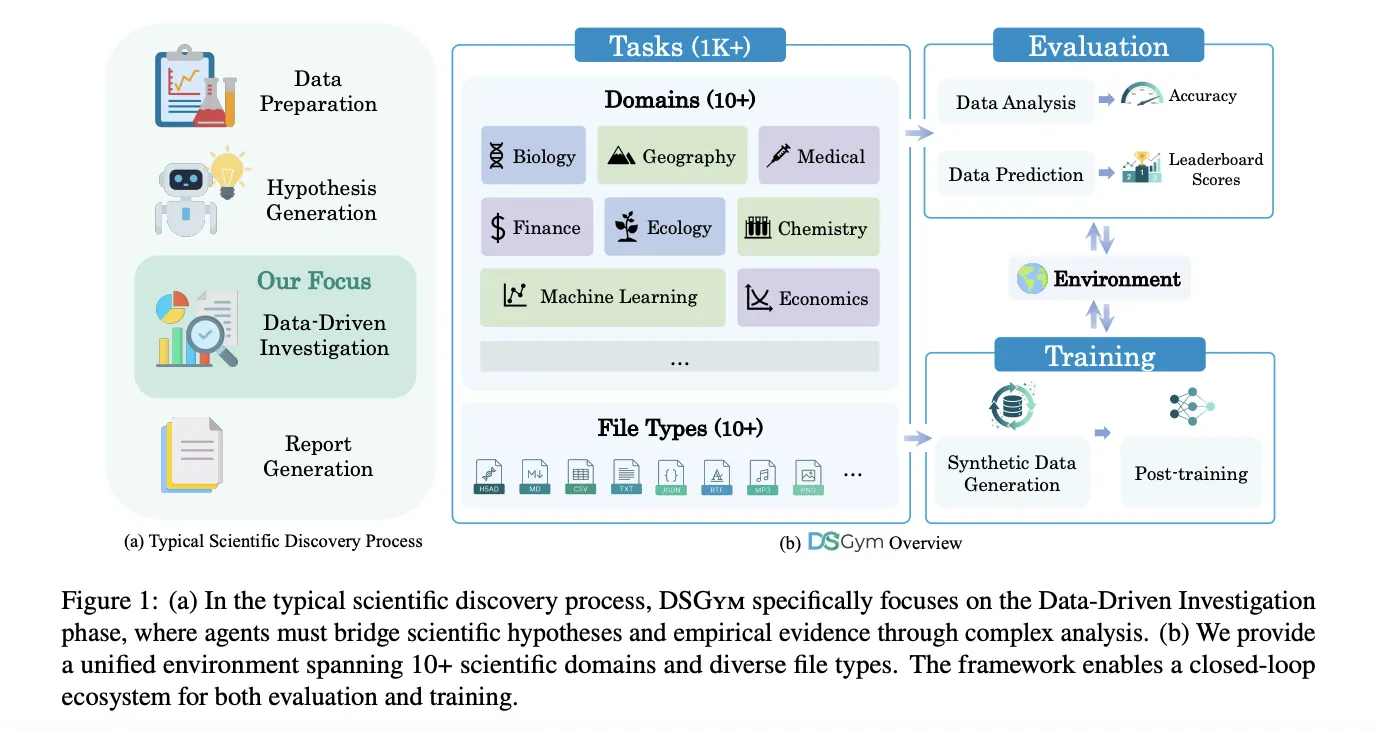
En el mundo de la IA y el machine learning, evaluar y entrenar agents de data science de manera fiable es un reto constante. Aquí es donde entra DSGym, un nuevo framework holístico y modular que promete revolucionar cómo las empresas abordan estas tareas. Su propuesta es simple pero potente: ofrecer entornos de ejecución aislados y reproducibles, ideales para evaluar y entrenar agentes que manejan datos complejos, todo dentro de contenedores Docker.
¿Qué Problema Resuelve DSGym para tu Negocio?
Los benchmarks tradicionales a menudo fallan. Tienen interfaces inconsistentes, una cobertura limitada de tareas y, lo que es más crítico, no garantizan que los agentes interactúen genuinamente con los datos. DSGym nace de la observación de que muchos ‘hallazgos’ de IA actuales se resuelven sin un acceso real y verificado a los datos, lo que los hace inútiles en un contexto empresarial real. Este framework aborda estas limitaciones de frente, asegurando que tus modelos y agentes se prueben en condiciones que simulan la realidad de tu negocio.
La clave de su arquitectura es un sistema manager-worker basado en contenedores Docker. El manager orquesta contenedores worker dedicados por cada tarea, proveyendo datasets de solo lectura y workspaces escribibles de forma aislada. Cada worker ejecuta un kernel Jupyter independiente, lo que garantiza el aislamiento total de entornos Python, la persistencia del estado (variables, modelos entrenados) y límites claros de recursos (CPU, memoria, tiempo). Esto es crucial para flujos de trabajo exploratorios de data science que requieren una ejecución iterativa y con estado.
Análisis Blixel: La Relevancia de DSGym para PYMEs
Para una PYME, esto significa un cambio de juego. DSGym elimina la complejidad de configurar entornos de prueba y entrenamiento. Con este framework, puedes asegurarte de que tus modelos de IA no solo ‘funcionan’ en papel, sino que lo hacen de manera robusta y reproducible con tus datos, sin riesgos de filtraciones o dependencias caóticas. La capacidad de curar y estandarizar tareas bajo una API unificada, junto con la detección de ‘atajos’ que no implican interacción real con datos, te da una garantía de calidad que antes era difícil de alcanzar.
Imagínate poder probar nuevos modelos de IA con la confianza de que los resultados son válidos y que los agentes realmente comprenden y procesan tus datos. Esto no solo ahorra tiempo y recursos, sino que también minimiza el riesgo de tomar decisiones empresariales basadas en IA defectuosa. La escalabilidad es otro punto fuerte: la capacidad de ejecutar cientos de trayectorias en paralelo abre la puerta a la experimentación masiva sin inversiones desorbitadas en infraestructura. Es una herramienta poderosa para cualquier negocio que quiera llevar su estrategia de datos al siguiente nivel, especialmente en áreas como bioinformática (DSBio) o predicciones avanzadas (DSPredict). DSGym es, en esencia, una inversión en fiabilidad y eficiencia para tu estrategia de IA.
Las características técnicas clave incluyen la protección del sistema de archivos (montajes de solo lectura), el uso de contenedores específicos de dominio y el ciclo de entornos para una escalabilidad paralela masiva. Además, la verificación post-ejecución en procesos limpios asegura la integridad de los resultados. El equipo detrás de este proyecto ha demostrado su capacidad: generaron 2.000 ejemplos de entrenamiento y fine-tunearon un modelo de 4B parámetros que superó a GPT-4o en benchmarks estandarizados con ayuda de DSGym.
DSGym se posiciona como una plataforma extensible y comunitaria, facilitando la adición de nuevas tareas, la integración de agentes y herramientas. Esto fomenta una evaluación rigurosa y el desarrollo de agents de data science capaces de planificar, implementar y validar análisis basados en datos en escenarios científicos y empresariales realistas.
Fuente: Marktechpost
{kind=link}
Deja una respuesta