La implementación de agentes de Modelos de Lenguaje Grandes (LLM) autónomos en entornos empresariales abre un abanico de posibilidades, pero también de riesgos. Investigadores de la Universidad de Tsinghua y Ant Group han abordado esta cuestión crítica presentando un robusto marco de seguridad de 5 capas para agentes LLM autónomos. Este enfoque holístico busca mitigar las vulnerabilidades inherentes a estos sistemas, cubriendo la totalidad de su ciclo de vida.
El desafío radica en que estos agentes integran capacidades visuales, lingüísticas y de acción, lo que multiplica las superficies de ataque. El nuevo marco, validado en sistemas como OpenClaw, ofrece una protección sistemática desde el diseño hasta el mantenimiento, asegurando que su IA no se convierta en un punto débil para su negocio. Para una PYME, esto significa que el coste de un incidente de seguridad en IA podría ser significativo, por lo que entender y aplicar estas capas es crucial.
Un Marco de Seguridad de 5 Capas: Clave para la IA de Negocios
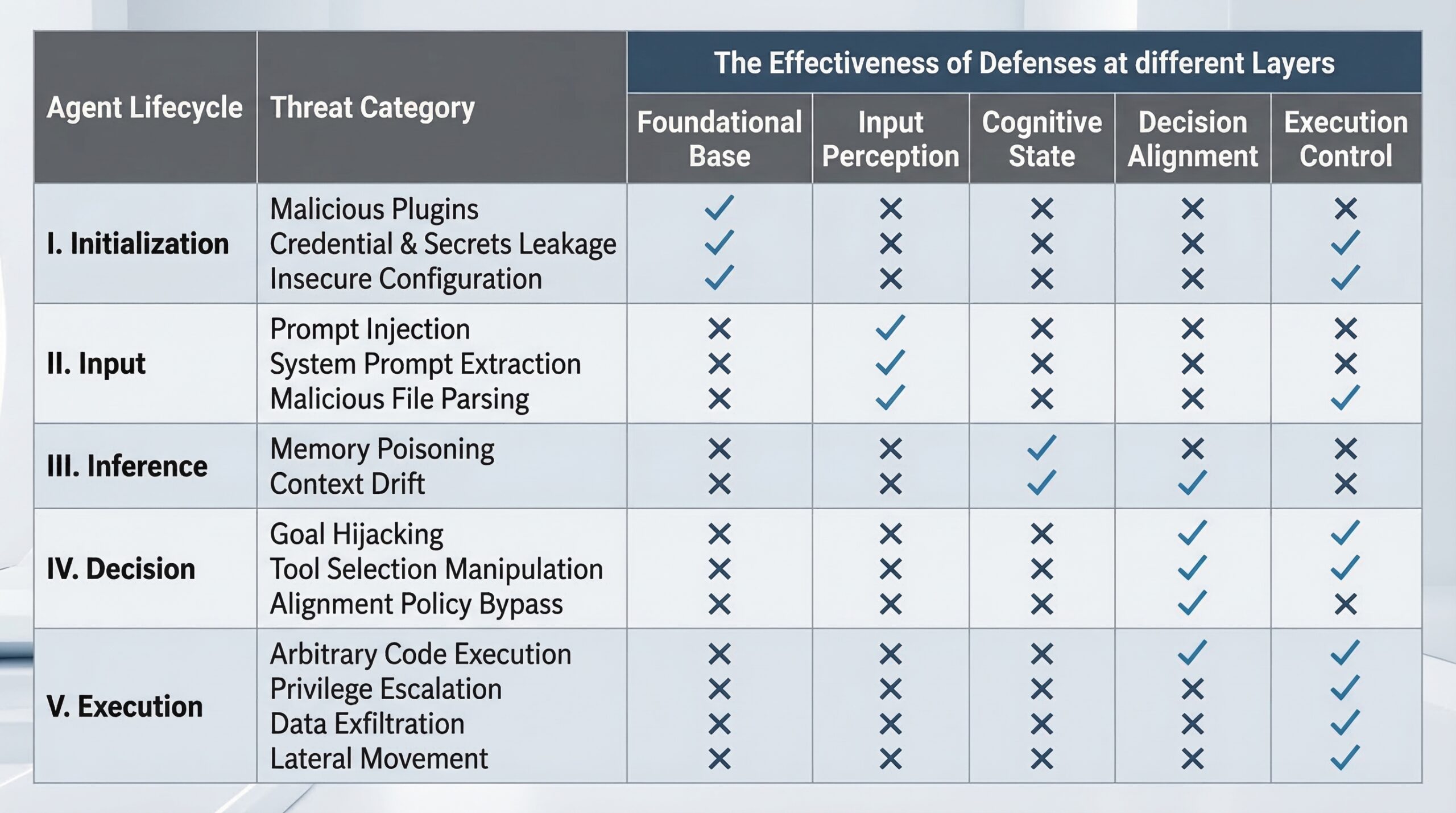
Este marco de seguridad de 5 capas para agentes LLM autónomos se estructura en:
- Análisis de amenazas en el diseño: Antes de escribir una línea de código, se identifican posibles puntos débiles: inyección de prompts, fuga de datos sensibles o comportamientos inesperados.
- Controles preventivos: Durante el desarrollo, se implementan validación de entradas, sandboxing para acciones en entornos controlados y monitoreo en tiempo real de decisiones. Esto es vital para detener problemas antes de que escalen.
- Despliegue seguro: Ya en producción, se configuran autenticaciones multi-factor para herramientas externas y límites de tasa en las API. Medidas básicas, pero a menudo pasadas por alto, que evitan el abuso.
- Detección y respuesta automatizadas: En operación, se utilizan modelos de detección de anomalías basados en LLM para identificar comportamientos extraños y activar respuestas automáticas, como rollbacks o cuarentenas.
- Evaluación continua y actualización: La seguridad no es estática. Este pilar implica retroalimentación de incidentes y auditorías periódicas para adaptar las políticas de seguridad.
Este sistema ha demostrado una reducción del 85% en las tasas de éxito de exploits comunes en pruebas con OpenClaw, sin comprometer el rendimiento. Un aspecto destacable es la integración de logging interpretable y explicabilidad basada en grafos de atención, lo que facilita enormemente la depuración forense post-incidente. Para una empresa, esto se traduce en una mayor confianza al implementar soluciones de IA y una capacidad de respuesta mucho más rápida ante cualquier ataque.
Análisis Blixel: Más allá de la teoría, ¿cómo afecta a su PYME?
Este marco de seguridad de 5 capas para agentes LLM autónomos no es mera teoría académica; representa un manual de supervivencia para cualquier empresa que quiera subirse al tren de la IA sin que el vagón descarrile. En Blixel, entendemos que los recursos en una PYME son limitados, por lo que la clave es la priorización. No puede implementar todo a la vez, pero sí puede integrar los principios clave de este marco.
Primero, la prevención: invierta en validación rigurosa de entradas y un sandbox para sus agentes. Segundo, la monitorización: no espere a que sea tarde, implemente detección de anomalías. Tercero, la mejora continua: revise regularmente sus políticas de seguridad en IA. La visibilidad que ofrecen el logging interpretable y la explicabilidad no es un lujo; es una necesidad. Le permitirá entender qué falló y por qué, ahorrándole tiempo y dinero en una crisis.
{kind=link}
Deja una respuesta