En el cambiante panorama de la inteligencia artificial, la eficiencia es clave. Recientemente, Mistral AI ha dado un golpe sobre la mesa con el lanzamiento de Mistral Small 4, un modelo Mixture of Experts (MoE) de 119 mil millones de parámetros. Este lanzamiento no es solo una ficha más en el tablero, sino una evolución significativa en cómo entendemos los modelos compactos de alto rendimiento, pensados específicamente para workloads empresariales y el tan prometedor edge computing.
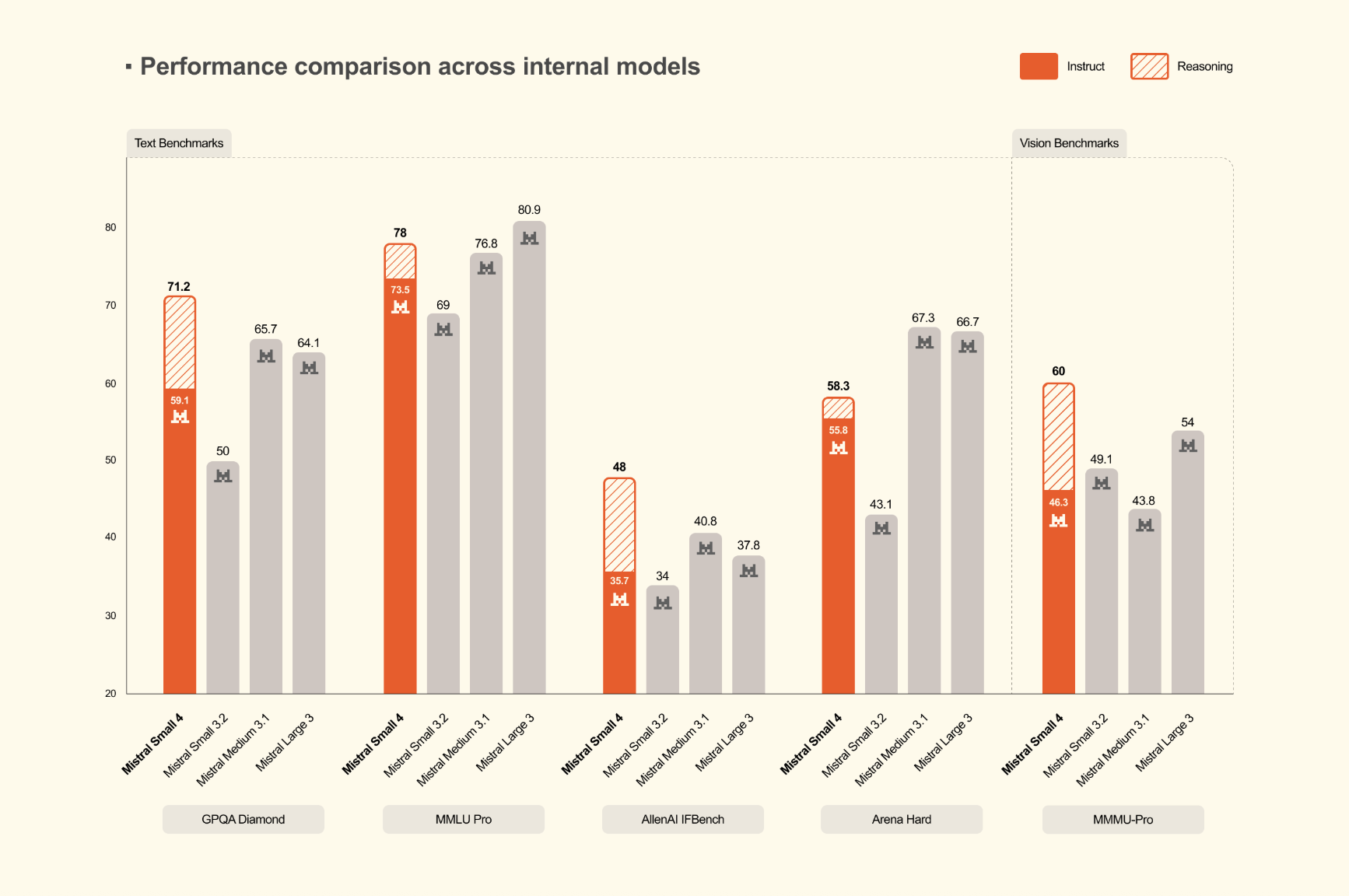
La arquitectura MoE es el corazón de esta innovación. Permite activar solo subconjuntos de parámetros durante la inferencia, lo que se traduce en una eficiencia operativa que compite con modelos densos mucho más pequeños, manteniendo a su vez el rendimiento de los llamados ‘frontier models’. Esto significa que tu empresa podría obtener resultados de IA de vanguardia sin la necesidad de infraestructuras masivas y costosas. Mistral Small 4 integra visión nativa, razonamiento complejo y procesamiento multilingüe, con ventanas de contexto de hasta 256k tokens, superando a competidores en benchmarks estandarizados.
Mistral Small 4: Diseñado para Negocios y Eficiencia
Mistral AI sigue apostando por su estrategia: lanzar modelos pequeños, pero potentes. Este enfoque ya lo vimos con la familia Ministral 3 (3B, 8B, 14B parámetros) y Mistral Large 3 (41B activos/675B totales). Lo que hace especial a estos modelos es su capacidad de superar a LLMs cerrados y masivos en custo/beneficio y latencia, una vez que se han optimizado y fine-tuned para casos de uso reales de negocio. Esto no es una promesa vacía; hablamos de la posibilidad de desplegar estos modelos offline en dispositivos como smartphones, robots, drones y vehículos, abriendo puertas a colaboraciones en sectores críticos como ciberseguridad, defensa y automoción.
La disponibilidad de todos estos modelos bajo licencia Apache 2.0 es un punto crucial. Esto fomenta la adopción por parte de la comunidad de desarrolladores y promueve lo que llamamos ‘distributed intelligence’, es decir, una IA más accesible y descentralizada. El entrenamiento de Mistral Small 4 se realizó en 3000 GPUs H200 de NVIDIA, demostrando su capacidad para lograr paridad de rendimiento con los mejores modelos instruction-tuned en prompts generales, comprensión de imágenes y conversaciones multilingües (no solo inglés/chino).
Análisis Blixel: Más allá del tamaño, la inteligencia
Desde Blixel, vemos con claridad que este movimiento de Mistral AI no es solo técnico, es estratégico. Desafía directamente la idea de que ‘más grande es siempre mejor’ en el mundo de los LLMs. Para una PYME, esto significa una redefinición de lo que es posible. Antes, acceder a una IA de vanguardia con capacidad multimodal y de razonamiento requería inversiones que pocos podían justificar. Ahora, con Mistral Small 4, la barrera de entrada se reduce drásticamente.
Nuestra recomendación es clara: si tu negocio está explorando cómo integrar IA, especialmente en escenarios donde la latencia, el costo operativo o la privacidad son críticos (por ejemplo, procesamiento de datos sensibles localmente, optimización de flotas con IA en el borde, o desarrollo de asistentes virtuales omnicanal), Mistral Small 4 merece una evaluación profunda. No solo por su rendimiento, sino por la eficiencia que promete en un contexto donde cada recurso cuenta. Es una oportunidad para democratizar la IA avanzada y ponerla al servicio de procesos de negocio que antes eran impensables.
Fuente: Marktechpost
{kind=link}
Deja una respuesta