
NVIDIA ha introducido una innovación significativa para la inferencia de Grandes Modelos de Lenguaje (LLMs) con su tecnología NVIDIA KVTC (KV-cache Transform Coding). Esta herramienta promete reducir el tamaño de los caches clave-valor (KV) hasta 20 veces, lo que se traduce directamente en una mejora sustancial del rendimiento y la eficiencia en el uso de la memoria, algo crítico para las empresas que despliegan LLMs a gran escala. Para cualquier PYME que dependa de la IA, entender qué significa esto y cómo impacta su infraestructura es fundamental.
NVIDIA KVTC: Optimizando la Memoria para Mejorar el Rendimiento
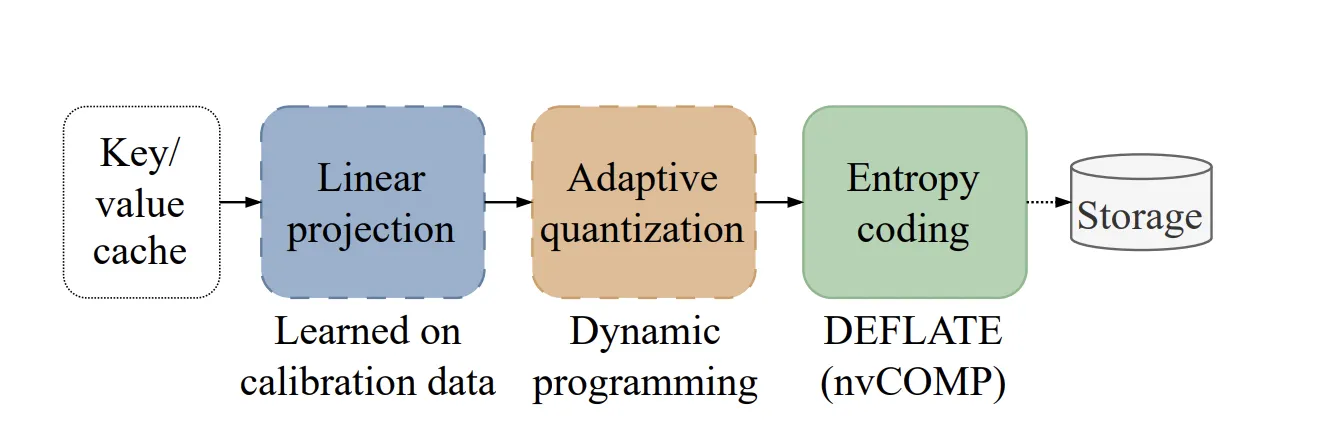
El KV-cache es un componente vital en la arquitectura de los LLMs. Almacena las representaciones clave y valor de tokens procesados, evitando recalcularlos en cada paso de generación. Sin embargo, su tamaño crece linealmente con la longitud de la secuencia, consumiendo una cantidad desproporcionada de memoria GPU, especialmente en contextos largos y cuando se sirve a múltiples usuarios. Aquí es donde NVIDIA KVTC entra en acción. Se inspira en códecs de medios clásicos, utilizando una combinación de decorrelación basada en PCA, cuantización adaptativa y codificación de entropía para lograr una compresión sin pérdidas.
Lo interesante es que KVTC no modifica los parámetros del modelo, lo que simplifica su implementación. Requiere solo una calibración inicial breve (unos 10 minutos en una H100 para un modelo de 12B), que se encarga de recolectar datos y ajustar los parámetros de compresión. Esto significa que la integración en flujos de trabajo existentes es sorprendentemente directa, tal como ha demostrado NVIDIA.
Análisis Blixel: Más allá de los milisegundos, el valor de NVIDIA KVTC
Como Sofía Navarro, mi visión es pragmática: ¿cómo aterriza esto en la realidad de vuestros negocios? La promesa de NVIDIA KVTC no es solo una cifra técnica; es una ventaja competitiva. Para quien esté operando LLMs, ya sea para atención al cliente, generación de contenido o análisis de datos, la memoria GPU es oro. Reducir su consumo en 20x significa que podéis servir a más usuarios con el mismo hardware, procesar contextos más largos sin incurrir en costes exorbitantes, o incluso reutilizar caches en conversaciones con prefijos compartidos.
La implementación de KVTC en HuggingFace Transformers es una señal clara de su accesibilidad. Esto no es solo para los gigantes tecnológicos; es una herramienta que las PYMEs con infraestructuras de IA pueden comenzar a explorar hoy mismo para optimizar sus operaciones. La mejora del Time-to-First-Token (TTFT) es otro punto clave: tiempos de respuesta más rápidos se traducen en una mejor experiencia de usuario y una mayor eficiencia operativa. En un mundo donde la latencia es crucial, esto puede marcar la diferencia entre una buena y una excelente interacción con la IA, directamente impactando la percepción del cliente y la productividad interna.
Impacto Directo: Rendimiento Comprobado y Aplicaciones Reales
Los benchmarks son claros. NVIDIA KVTC no solo comprime el KV-cache, sino que lo hace manteniendo la precisión en tareas críticas de razonamiento y contexto largo. Se ha probado en modelos como Llama 3.1, Mistral-NeMo 12B y R1-Qwen 2.5, superando a otros métodos de compresión.
En inferencia multi-GPU, por ejemplo, con Llama 3.3 70B, se logró una compresión de 20x con una degradación mínima de precisión (solo 3 puntos porcentuales en MATH500). Pero donde el impacto es más tangible para las operaciones diarias es en la mejora del Time-to-First-Token (TTFT). NVIDIA ha reportado reducciones drásticas, pasando de 3098ms a 380ms en escenarios de alta carga. Esto no es ciencia ficción; son milisegundos que se traducen en una experiencia más fluida para el usuario final y una menor carga para vuestros servidores. La capacidad de soportar un trade-off suave entre tasa de compresión y precisión (logrando más de 40x con un coste moderado) ofrece flexibilidad para adaptarse a distintas necesidades empresariales.
La disponibilidad de KVTC en HuggingFace Transformers y su compatibilidad con nvCOMP y entornos on-GPU/CPU facilitan su adopción. Para las empresas, esto significa una oportunidad real de escalar sus aplicaciones de LLMs sin tener que invertir masivamente en nuevo hardware, simplemente optimizando lo que ya tienen con la tecnología que NVIDIA KVTC proporciona.
Fuente: Marktechpost
{kind=link}
Deja una respuesta