
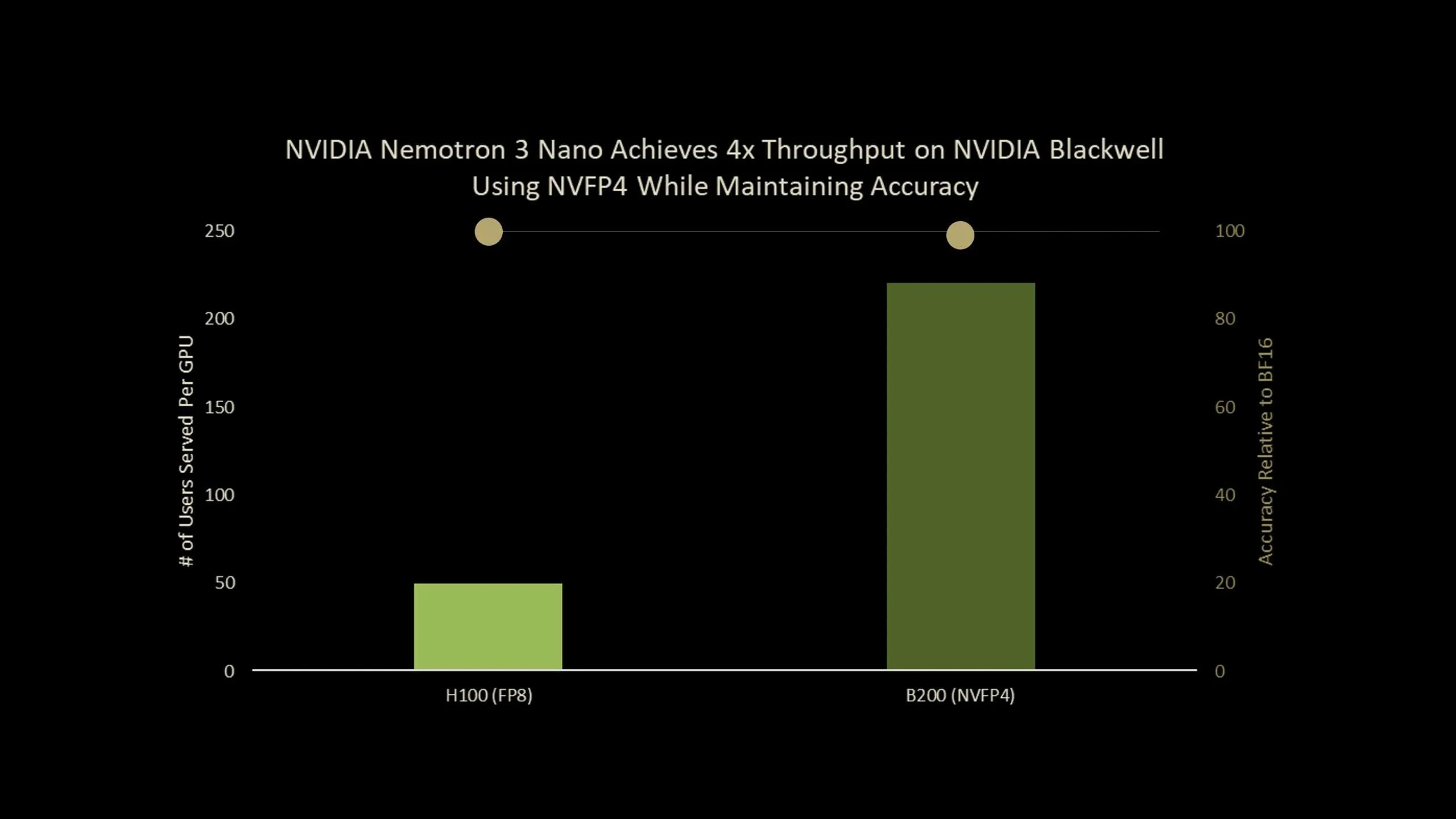
NVIDIA ha dado un paso significativo en el terreno de la inteligencia artificial con el lanzamiento de una versión optimizada de su modelo NVIDIA Nemotron 3 Nano 30B. Este desarrollo no es un simple ajuste, sino una redefinición de eficiencia, especialmente relevante para empresas que buscan implementar soluciones de IA avanzadas sin sacrificar rendimiento ni disparar costes. La clave reside en su ejecución en precisión NVFP4 y el uso de Quantization-Aware Distillation (QAD), que permite mantener una alta precisión mientras se logra hasta cuadruplicar el rendimiento en GPUs B200 en comparación con FP8 en H100.
NVIDIA Nemotron 3 Nano 30B: un salto en la eficiencia de agentes de IA
El Nemotron 3 Nano 30B está específicamente diseñado para potenciar aplicaciones de agentes de IA. ¿Qué significa esto para una PYME? Que tareas complejas como la automatización de atención al cliente, el análisis financiero avanzado o la detección proactiva de ciberamenazas, pueden ejecutarse con una eficiencia y una capacidad que antes eran inalcanzables. Su arquitectura híbrida Mamba-Transformer MoE (Mixture of Experts) es un ejemplo claro de cómo la innovación puede reducir los requisitos computacionales. Con 30B de parámetros totales pero solo 3B activos por token, este modelo gestiona una ventana de contexto de 1 millón de tokens, lo que es vital para manejar grandes volúmenes de información sin divisiones de texto agresivas (chunking).
La capacidad de este modelo para optimizar la precisión mediante un ‘thinking budget’ es otra característica destacada. En lugar de procesar información de manera redundante, el modelo evalúa cuánto ‘pensar’ es necesario, mitigando el sobrepensamiento y controlando costes. Fue entrenado con 10 billones de tokens curados por NVIDIA, abarcando campos como el desarrollo de código, razonamiento científico, matemáticas, llamadas a funciones y seguimiento de instrucciones, lo que lo hace versátil para una amplia gama de aplicaciones empresariales. Los resultados en benchmarks como SWE Bench Verified (codificación), GPQA Diamond (razonamiento científico) y Arena Hard v2 son consistentes, superando a modelos abiertos como Qwen3-30B y GPT-OSS-20B.
Análisis Blixel: Implicaciones para la pyme con NVIDIA Nemotron 3 Nano 30B
Desde Blixel, vemos este lanzamiento como una oportunidad tangible para que muchas pymes den un salto cualitativo en su estrategia de IA. La promesa de inferencia ultraeficiente no es solo una cifra técnica, es la posibilidad de reducir costes operativos al requerir menos recursos de hardware, o de escalar sus operaciones de IA sin una inversión inicial prohibitiva. Imaginen tener agentes de IA que pueden gestionar interacciones complejas con clientes, analizar grandes datasets para identificar riesgos financieros o incluso asistir en el desarrollo de software de forma más ágil y precisa.
La clave aquí es la aplicación práctica. Para una startup en ciberseguridad, esto podría significar una detección de amenazas más rápida y con menos falsos positivos. Para una empresa de retail, la personalización de la experiencia del cliente a una escala antes imposible. El soporte en una variedad de plataformas conocidas como vLLM, SGLang o TensorRT-LLM, y la compatibilidad con hardware desde H100 hasta GeForce RTX, democratiza el acceso a estas capacidades. Este es el momento de evaluar cómo la eficiencia de NVIDIA Nemotron 3 Nano 30B puede integrarse en procesos críticos, no solo para mejorar la eficiencia, sino para descubrir nuevas vías de negocio.
La hoja de ruta de NVIDIA con los futuros Nemotron 3 Super y Ultra (100B y 500B de parámetros respectivamente) para H1 2026, conlatent MoE y multi-token prediction, solo confirma una dirección clara: modelos abiertos y altamente optimizados para agentes que pueden manejar sesiones prolongadas y documentos complejos. Esto es especialmente relevante en sectores como finanzas o ciberseguridad, donde el contexto lo es todo y la interacción prolongada con grandes volúmenes de datos es una constante.
Fuente: Marktechpost
{kind=link}
Deja una respuesta