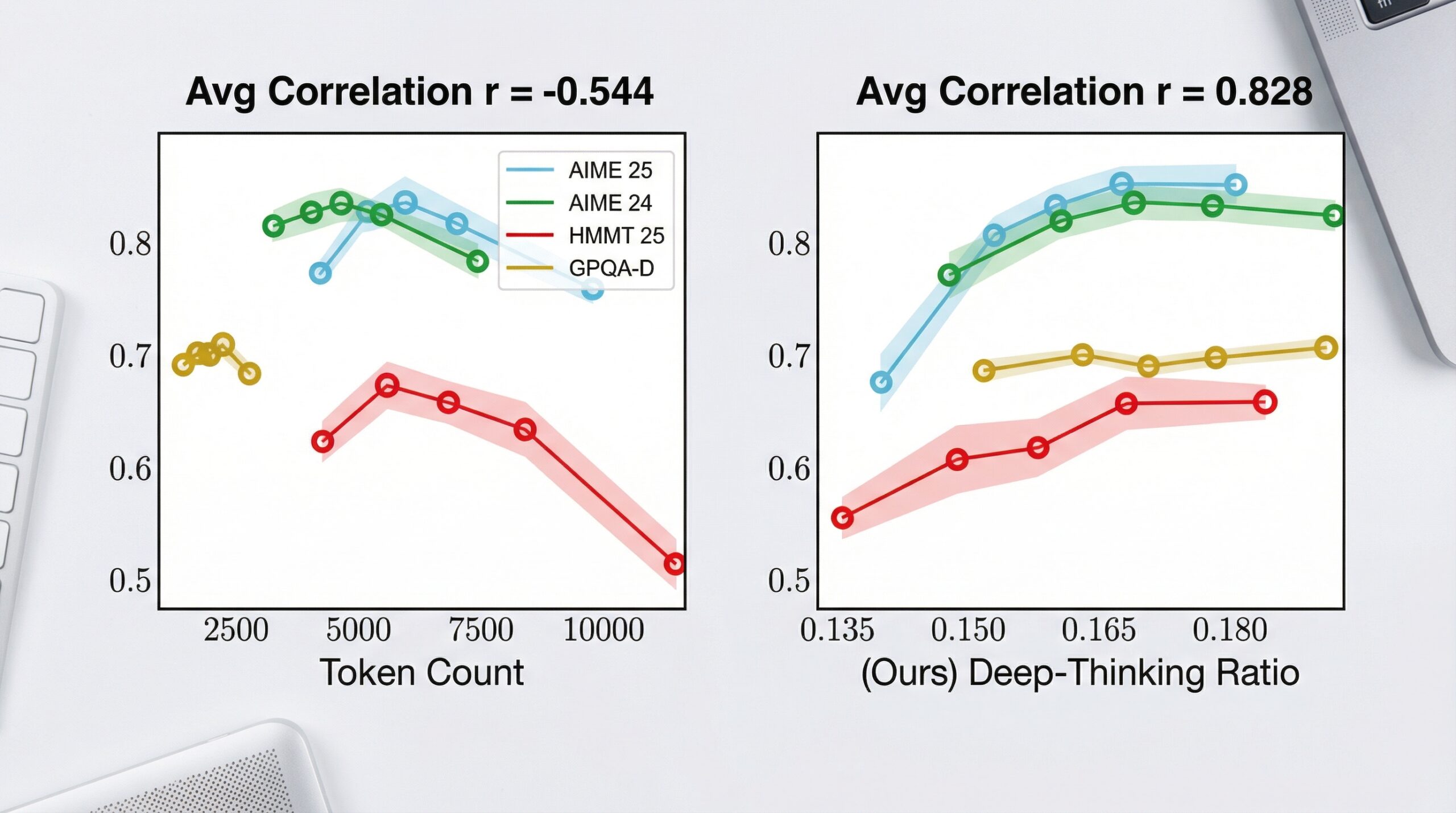
Google AI ha lanzado una propuesta que nos interesa, y mucho, a las empresas que buscamos optimizar nuestros recursos. Hablamos del Deep Thinking Ratio (DTR), una métrica que promete revolucionar la eficiencia de los Modelos de Lenguaje Grandes (LLM). ¿El objetivo? Mejorar la precisión de los LLM mientras reducimos drásticamente los costes de inferencia, hasta en un 50%. Una auténtica tabla de salvación para muchas PYMEs que ven el despliegue de IA avanzada como una inversión inalcanzable.
Google Deep Thinking Ratio: ¿Qué Implica Para Tu Negocio?
El DTR se asienta sobre la idea de «pensamiento» interno del modelo antes de generar una respuesta. Imagina que tu LLM no solo responde, sino que razona internamente, verifica y ajusta su lógica antes de darte la solución final. Esta técnica, conocida como test-time compute, permite al modelo generar cadenas de razonamiento intermedias, ajustándose a la complejidad de cada tarea. No se trata de escalar el cómputo linealmente, como antes, sino de identificar el punto óptimo donde más «pensamiento» no equivale a una mejor respuesta, o al menos, no una respuesta que justifique el coste adicional.
Los investigadores de Google han demostrado que este enfoque puede mejorar la precisión de los LLM entre un 20% y un 30%, a la vez que reduce los costes totales de inferencia a la mitad. Esto significa que una pyme podría acceder a la misma calidad de resultados de IA, con un coste operativo significativamente menor, o incluso mejorar la calidad de sus aplicaciones actuales sin disparar el presupuesto. Este es un punto crítico porque el consumo computacional y la latencia son barreras habituales para la adopción de modos de ‘Deep Think’ más complejos. La flexibilidad del DTR para asignar recursos dinámicamente según la complejidad de la tarea es un cambio de juego.
Análisis Blixel: Tu Estrategia con el Deep Thinking Ratio
Desde Blixel, vemos en el Deep Thinking Ratio una oportunidad tangible para las empresas. No estamos hablando de otra promesa etérea de Google, sino de una técnica con resultados cuantificables que ya se está testando en benchmarks como MMLU-Pro y GPQA. Si dependes de LLM para atención al cliente, generación de contenido, análisis de datos o cualquier otra aplicación, la optimización que ofrece este ratio es clave. Un DTR de 4:1 (cuatro tokens de pensamiento por cada uno de respuesta) está mostrando un equilibrio ideal entre calidad y coste en tareas complejas.
¿Qué puedes hacer ahora? Mantente al tanto de la evolución de esta tecnología. Empieza a analizar los costes actuales de tus implementaciones de IA y considera pilotos con modelos que incorporen lógicas de DTR cuando estén disponibles comercialmente. Prepara a tu equipo técnico para entender cómo adaptar las solicitudes a los LLM para aprovechar estos ‘tokens de pensamiento’ y cómo monitorizar la eficiencia. La clave aquí es la acción: no esperes a que sea el estándar, investiga cómo puedes ser de los primeros en integrar esta eficiencia en tus operaciones.
Finalmente, este enfoque resuelve limitaciones históricas de los modos ‘Deep Think’, que solían ser prohibitivamente caros y lentos. Al destilar estos razonamientos verificados, incluso consiguen transferir estas ganancias a modelos más pequeños, con la mitad de parámetros. El impacto potencial en aplicaciones como agentes autónomos, I+D científico y codificación es inmenso, abriendo la puerta a una adopción más amplia de la IA avanzada sin la necesidad de una infraestructura descomunal.
Fuente: Marktechpost
{kind=link}