
Meta, una vez más, nos da una lección práctica en la gestión de infraestructuras críticas. Han liberado GPU Cluster Monitoring (GCM), una suite de herramientas diseñada para el monitoreo proactivo de clústeres de GPU a gran escala. Esto no es solo una novedad técnica; es una solución directa que busca atajar un problema común y costoso en el desarrollo de IA: los fallos inesperados en el hardware. Para las empresas que dependen de clústeres de GPU, entender y aplicar esta herramienta puede significar una diferencia abismal en eficiencia y costes operacionales.
Meta GCM: Vigilando el Corazón de la IA Empresarial
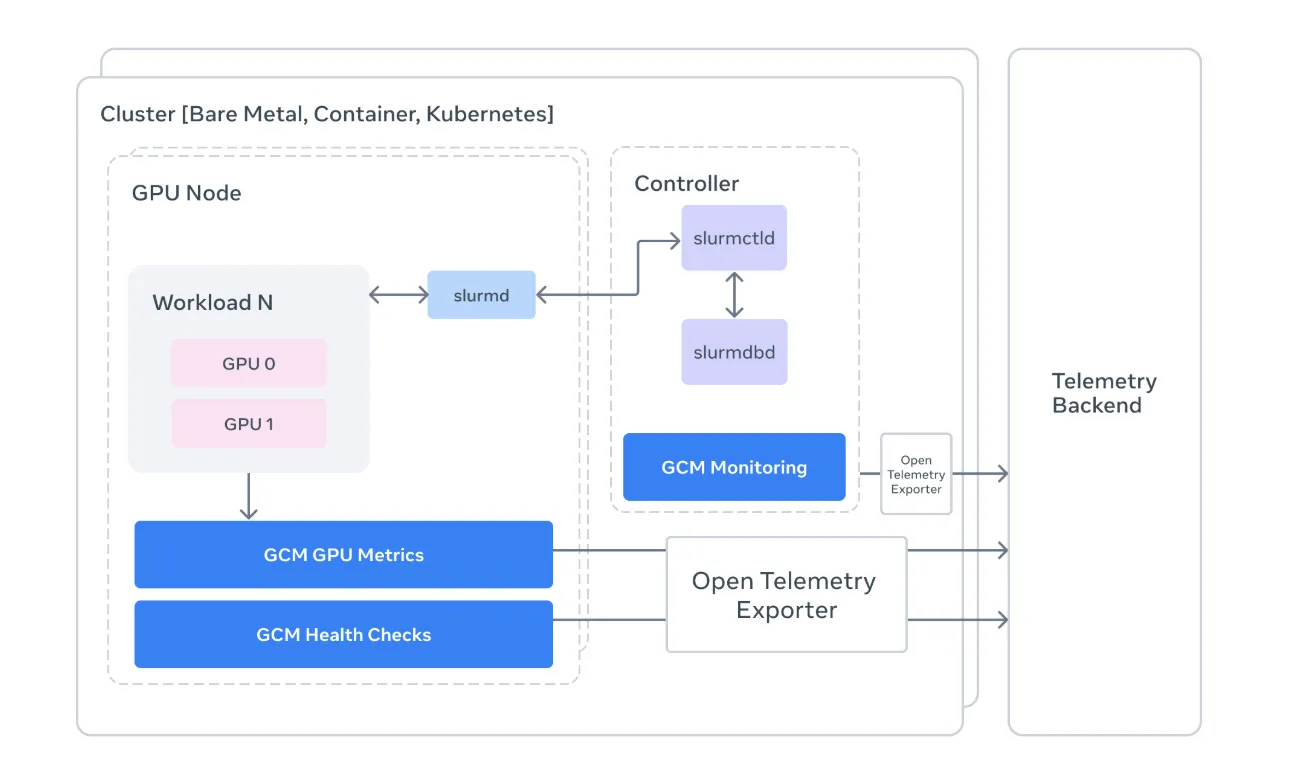
La esencia de Meta GCM radica en su capacidad para anticiparse a los problemas. La investigación interna de Meta, basada en clústeres de entrenamiento de 1,024 GPUs, reveló un dato preocupante: el tiempo medio hasta el fallo (MTTF) es de apenas 7.9 horas. Eso es un cuello de botella constante para cualquier proyecto de IA serio. GCM, con su monitoreo constante de 305 métricas cada 30 segundos, abarca todos los dominios críticos: GPU, red, almacenamiento y el planificador. Esto permite a empresas como Lablup (socio de Upstage en el proyecto Sovereign AI Foundation Model) implementar detección proactiva de fallos en clústeres de hasta 500 GPUs.
Lo interesante es cómo GCM cambia la comprensión de dónde residen los problemas. Contraintuitivamente, los errores de NVLink, que conectan las GPUs, representan el 23.5% de los fallos, superando por mucho los errores ECC (11.8%) que en estudios previos acaparaban la atención. Además, mientras que las métricas de GPU solo representan el 6% del total de las causas de fallos, la red, el almacenamiento y la memoria conforman un sorprendente 52%. Esto subraya la necesidad de una visión holística que GCM proporciona, lejos de las soluciones de monitoreo aisladas.
Análisis Blixel: Más Allá del Hardware, la Eficiencia
Desde Blixel, vemos en Meta GCM una oportunidad clara para cualquier PYME o startup trabajando con IA que aspire a la escalabilidad. No se trata solo de tener GPUs potentes, sino de mantenerlas operativas. Perder horas de cómputo por un fallo no detectado no es una opción cuando los recursos son limitados y el tiempo es oro.
Nuestra recomendación es clara: si usas o planeas usar infraestructuras de clústeres de GPU, evalúa seriamente herramientas de monitoreo proactivo como GCM. La clave está en entender que los fallos rara vez son solo del chip gráfico; la red, el almacenamiento y el sistema de planificación son igual de críticos. Implementar un monitoreo amplio y no solo profundo en un único componente te permitirá anticipar problemas, reducir costes operativos y mantener tus proyectos de IA a flote. Esto es eficiencia de verdad, no palabrería.
La detección de fallos por cascadas es otro punto fuerte. Cuando una GPU se ralentiza, GCM detecta cómo los datos se acumulan, las colas de I/O aumentan y la carga del sistema se dispara. El sistema incluso capta indicadores indirectos como retransmisiones TCP o desviaciones de sincronización temporal. Esto demostró ser crucial en un caso donde la señal más temprana de un fallo de GPU no provino de las métricas de la GPU, sino de las métricas del planificador. Este enfoque amplio y multi-dominio es, sin duda, la dirección correcta para garantizar la fiabilidad.
Fuente: Marktechpost
{kind=link}