Gigantes como ByteDance Protenix-v1 demuestran que la democratización de la IA avanzada es imparable. Recientemente, ByteDance ha liberado Protenix-v1, un modelo de código abierto que alcanza el rendimiento de AlphaFold3 (AF3) en la predicción de estructuras biomoleculares complejas, incluyendo proteínas, ADN, ARN y ligandos. Este lanzamiento no es solo un hito técnico, sino una señal clara de que las herramientas de IA más sofisticadas están volviéndose accesibles, abriendo puertas a empresas que antes no podían permitírselas.
Este avance es crucial porque acerca a muchas PYMES del sector biotecnológico herramientas que antes eran prohibitivas. Protenix-v1 se basa en el framework Protenix, destacando por su capacidad para predecir estructuras complejas con métricas altamente competitivas en benchmarks como LDDT para interfaces y complejos. La clave de su accesibilidad es Protenix-Mini, una variante ligera que reduce drásticamente la complejidad computacional sin sacrificar la precisión, lo que significa que ya no necesitas la infraestructura de un gigante para hacer investigación de vanguardia.
Impacto de ByteDance Protenix-v1 en la eficiencia computacional
La eficiencia es el santo grial de muchos desarrollos en IA, y con ByteDance Protenix-v1 no es diferente. Una de sus optimizaciones más notables es el reemplazo del muestreo multi-paso de AF3 por un sampler ODE de pocos pasos. ¿Qué significa esto? Que se reduce drásticamente el coste computacional durante la inferencia, sin comprometer la calidad. Un sampler ODE de tan solo 2 pasos puede lograr resultados casi idénticos a los de 200 pasos, como se ve en un LDDT de 0.645 en interfaces ligando-proteína versus 0.65 del baseline.
Además, el equipo de ByteDance realizó una «poda arquitectónica». Analizaron qué partes del modelo no contribuían significativamente y las eliminaron. Protenix-Mini, por ejemplo, usa solo 16 bloques pairformer y 8 bloques diffusion transformer, manteniendo una precisión impresionante. Esto traduce directamente en menos recursos necesarios para ejecutar el modelo, una ventaja enorme para cualquier empresa con limitaciones de presupuesto o infraestructura. En subconjuntos de PDB reciente, Protenix-Mini muestra reducciones marginales del 1-5% en métricas clave, un equilibrio excelente entre eficiencia y precisión.
Análisis Blixel: Más allá de la teoría, la aplicación real
Desde Blixel, vemos este tipo de lanzamientos como oportunidades tangibles para las PYMES. La liberación de Protenix-v1 por parte de ByteDance significa que ya no estamos hablando solo de grandes farmacéuticas o centros de investigación con presupuestos ilimitados. Ahora, una startup con talento y una infraestructura más modesta puede acceder a herramientas de predicción de estructuras biomoleculares que antes eran impensables.
Mi recomendación para nuestras empresas clientes es clara: explorad Protenix-v1. Si estáis en biotecnología, descubrimiento de fármacos o desarrollo de nuevos materiales, esta tecnología puede acelerar vuestra investigación y reducir costes. Podéis usarla para prototipado rápido, para validar hipótesis iniciales o para optimizar compuestos, sin necesidad de invertir millones en infraestructura. La clave es la democratización: la barrera de entrada para la investigación de alto nivel acaba de bajar drásticamente. Lo importante es ser ágil y experimentar con estas nuevas herramientas. No esperéis a que la competencia lo haga.
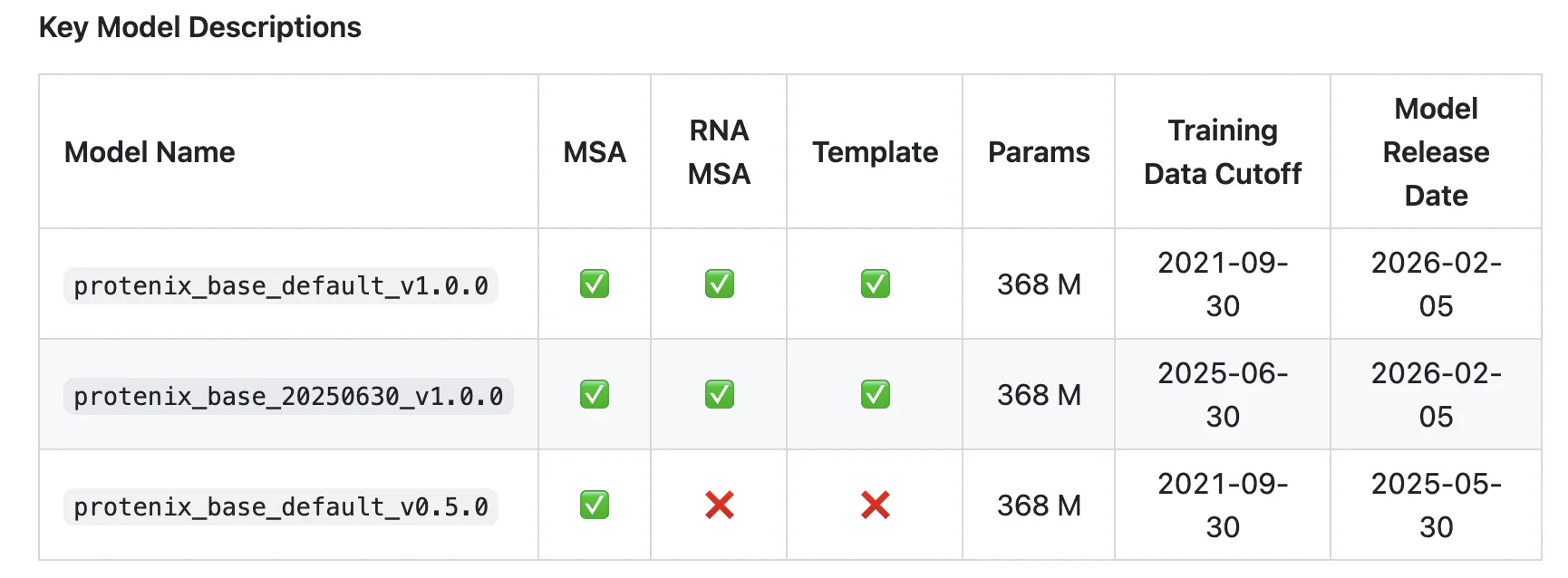
El repositorio GitHub de Protenix-v1 confirma la liberación del modelo con benchmarks detallados y actualizaciones continuas (v0.4.5), incluyendo mejoras en scripts MSA, formatos CIF y compatibilidad con hardware [4][5]. Para una accesibilidad aún mayor, Protenix Server ofrece predicciones para diversas moléculas [3], poniendo la potencia de ByteDance Protenix-v1 al alcance de un clic. Las futuras direcciones incluyen arquitecturas de atención sparse/adaptativa, destilación y cuantización, lo que significa que seguirá evolucionando para ser aún más eficiente y escalable.
Fuente: Marktechpost
{kind=link}